Agenta
Agenta is the open-source LLMOps platform that helps teams build reliable AI apps together.
Visit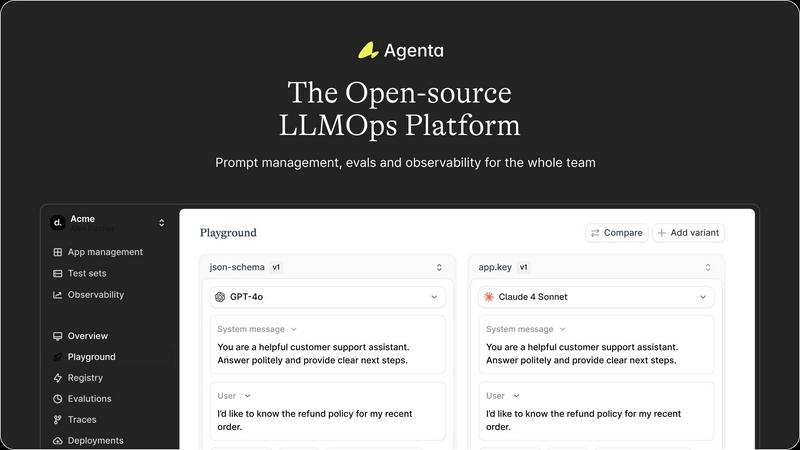
About Agenta
Agenta is the open-source LLMOps platform engineered to transform how AI teams build and scale. It directly tackles the core chaos of modern AI development, where prompts are scattered across communication tools, teams operate in silos, and deployment is a leap of faith. Agenta provides the essential infrastructure to implement a structured, collaborative, and evidence-based workflow, serving as the single source of truth for developers, product managers, and subject matter experts. It is built for teams serious about moving fast without breaking things, enabling them to iterate smarter, validate thoroughly, and scale their LLM applications efficiently from fragile prototypes to robust, production-grade systems. By centralizing prompt management, automated evaluation, and comprehensive observability, Agenta empowers teams to replace guesswork with data-driven decisions, debug with precision, and ship reliable AI features with confidence.
Features of Agenta
Unified Playground & Experimentation
Agenta provides a centralized playground where teams can iterate on prompts and compare different models side-by-side in real-time. This model-agnostic environment eliminates vendor lock-in, allowing you to use the best model from any provider. With complete version history for every prompt change, teams can track iterations, revert if needed, and maintain a clear audit trail of their development process, turning chaotic experimentation into a structured workflow.
Automated & Comprehensive Evaluation
Move beyond vibe checks with Agenta's systematic evaluation framework. It enables you to create a rigorous process to run experiments, track results, and validate every change before deployment. The platform supports any evaluator, including LLM-as-a-judge, custom code, and built-in metrics. Crucially, you can evaluate the full trace of an agent's reasoning, not just the final output, and seamlessly integrate human feedback from domain experts into the evaluation workflow.
Production Observability & Debugging
Gain deep visibility into your live LLM applications with comprehensive tracing. Agenta captures every request, allowing you to pinpoint exact failure points when things go wrong. You can annotate traces with your team or gather feedback directly from end-users. A powerful feature lets you turn any problematic production trace into a test case with a single click, closing the feedback loop and enabling continuous improvement based on real-world data.
Cross-Functional Collaboration Hub
Agenta breaks down silos by bringing product managers, domain experts, and developers into one unified workflow. It provides a safe, UI-based environment for non-technical experts to edit and experiment with prompts without touching code. Everyone can run evaluations, compare experiments, and contribute to the development process directly from the UI, while full API and UI parity ensures seamless integration between programmatic and manual workflows.
Use Cases of Agenta
Scaling Prototypes to Production
Teams with a working LLM prototype often struggle with the "last mile" to a reliable, scalable product. Agenta provides the structured workflow needed to systematically test, evaluate, and monitor changes. It replaces ad-hoc deployments with evidence-based releases, ensuring that performance improvements are real and regressions are caught early, dramatically increasing the success rate of launching AI features.
Centralizing Dispersed Prompt Management
When prompts are scattered across Slack, Google Sheets, and emails, consistency and version control are impossible. Agenta serves as the single source of truth for all prompt versions and configurations. This centralization prevents drift, allows for easy rollback, and ensures every team member is always working with the latest, approved iteration, eliminating costly errors and miscommunication.
Implementing Rigorous Evaluation Frameworks
For teams relying on manual "vibe testing," Agenta introduces a data-driven evaluation culture. You can build automated test suites that run against every proposed change, using LLM judges, code-based checks, and human-in-the-loop feedback. This creates a systematic gatekeeping process for production, building confidence that new prompts or model configurations actually improve key metrics before they impact users.
Debugging Complex Agentic Workflows
Debugging a failing LLM agent with multiple reasoning steps is notoriously difficult. Agenta's full-trace observability allows developers to see every intermediate step, input, and output. When an error occurs, engineers can drill down to the exact API call or reasoning step that failed, dramatically reducing mean-time-to-resolution (MTTR) and turning debugging from guesswork into a precise science.
Frequently Asked Questions
Is Agenta really open-source?
Yes, Agenta is a fully open-source platform. You can dive into the code on GitHub, contribute to the project, and self-host the entire platform. This ensures transparency, avoids vendor lock-in, and allows for deep customization to fit your specific infrastructure and workflow needs.
How does Agenta handle collaboration for non-technical team members?
Agenta features a dedicated, user-friendly web interface that allows product managers and domain experts to participate directly in the LLM development lifecycle. They can safely edit prompts in a visual playground, set up and view evaluation results, and provide feedback on traces without writing a single line of code, fostering true cross-functional collaboration.
Can I use Agenta with my existing tech stack?
Absolutely. Agenta is designed to be framework and model-agnostic. It seamlessly integrates with popular frameworks like LangChain and LlamaIndex, and can work with models from any provider, including OpenAI, Anthropic, Azure, and open-source models. It complements your existing tools rather than forcing a replacement.
What is the difference between evaluation and observability in Agenta?
Evaluation in Agenta refers to the systematic, often automated, testing of LLM variants against predefined metrics and test sets before deployment. Observability is about monitoring live, production systems, capturing traces, and gathering real-user feedback to detect issues and regressions. Agenta connects both: a production issue (observability) can instantly become a test case (evaluation), closing the loop.
Pricing of Agenta
Agenta is an open-source platform, and the core software is free to use. You can download, self-host, and modify it without any cost. For teams seeking a managed, cloud-hosted solution with additional enterprise features, support, and scalability, Agenta offers commercial plans. Detailed pricing tiers and specific costs for these premium offerings are available by contacting the sales team directly through the "Book a demo" or "Contact" links on their website.
Explore more in this category:
Similar to Agenta
JustLaunched
The launch platform for indie makers — schedule your launch, get in front of buyers, and blast across directories.

SeeCalc
SeeCalc is built and maintained by a single developer passionate about making marketing math fast, transparent, and free.