Crawlkit
CrawlKit empowers developers to effortlessly extract structured data from any website with a single API call.
Visit
About Crawlkit
Crawlkit is the ultimate web data extraction platform designed for developers and data teams seeking reliable, scalable access to web data without the burden of maintaining in-house scraping infrastructure. In today's complex web landscape, data extraction involves overcoming challenges such as rotating proxies, headless browsers, advanced anti-bot protections, rate limits, and frequent code breakages. Crawlkit simplifies this process by allowing users to send straightforward API requests, while it seamlessly manages proxy rotation, JavaScript rendering, automatic retries, and evasions against blocking mechanisms. This shift enables users to concentrate on high-value activities like data analysis, application development, and extracting actionable insights. With a developer-first philosophy, Crawlkit offers a unified API interface for extracting various data types, including raw HTML, structured search results, visual snapshots, and professional data from platforms like LinkedIn. Built for scalability, it boasts industry-leading success rates and rapid response times via a global edge network, empowering teams to construct robust data pipelines effortlessly.
Features of Crawlkit
Simple API Integration
Crawlkit provides a straightforward HTTP API that can be used from any programming language or platform, allowing developers to integrate it into existing workflows without restrictions or vendor lock-in.
Comprehensive Data Extraction
With just one API call, users can extract structured data from various sources including LinkedIn, Instagram, app stores, and more. Crawlkit simplifies complex data extraction processes into a single, efficient request.
Automatic Handling of Complexities
Crawlkit takes care of the intricate details of data extraction, such as managing proxies, rendering JavaScript, and handling rate limits. This allows users to focus on utilizing the data rather than worrying about how it is collected.
Transparent Pricing Model
Crawlkit operates on a credit-based pricing system with no hidden fees or surprise charges. Users can enjoy a straightforward understanding of costs, with credits that never expire and options for volume discounts as usage scales.
Use Cases of Crawlkit
CRM Enrichment
Crawlkit enables businesses to automate the enrichment of their Customer Relationship Management (CRM) systems by pulling valuable LinkedIn profile data, including job titles, company information, and contact details for each lead.
Social Media Monitoring
Companies can utilize Crawlkit to monitor competitors' social media growth, particularly on platforms like Instagram. Weekly tracking of follower counts, engagement rates, and top-performing posts helps businesses stay ahead of the competition.
App Review Analysis
With Crawlkit, organizations can efficiently gather and analyze app reviews from platforms like the App Store and Play Store. This allows teams to identify trends, assess user sentiment, and inform product development strategies.
Market Research
Crawlkit empowers teams to conduct thorough market research by extracting data from various websites and platforms. This structured data can be leveraged for competitive analysis, trend identification, and strategic decision-making.
Frequently Asked Questions
What types of data can I extract using Crawlkit?
Crawlkit allows you to extract various data types, including raw HTML, structured search results, visual snapshots, and professional data from platforms like LinkedIn and Instagram.
How does Crawlkit handle anti-bot protections?
Crawlkit is engineered to manage sophisticated anti-bot protections by using techniques like proxy rotation, JavaScript rendering, and automatic retries, ensuring successful data extraction even from challenging sites.
Is there a limit on API requests?
Crawlkit operates on a credit-based system with no monthly commitments or rate limits. Users can purchase credits based on their needs, and credits never expire, providing flexibility in usage.
Can I integrate Crawlkit with other tools?
Yes, Crawlkit's simple HTTP API is compatible with any programming language or automation tool, allowing seamless integration into existing workflows without any restrictions.
Explore more in this category:
Similar to Crawlkit
InContekst
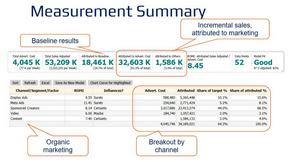
Decision support framework for high consideration businesses with mix of online and offline channels, content-rich sites, and long customer journeys.
EnsembleData
Unlock scalable growth with EnsembleData's real-time APIs for scraping social media posts, profiles, and analytics at scale.

Shadcn Examples
Ship production-ready UI faster with premium Shadcn components built for scalable React and Tailwind apps.
Subiq
Subiq simplifies SaaS subscription management for small teams, ensuring you track all tools, control spending, and avoid costly renewals.