Agenta vs OpenMark AI
Side-by-side comparison to help you choose the right product.
Agenta is the open-source LLMOps platform that helps teams build reliable AI apps together.
Last updated: March 1, 2026
OpenMark AI instantly benchmarks over 100 LLMs on your exact task for cost, speed, and quality with no setup or API keys.
Last updated: March 26, 2026
Visual Comparison
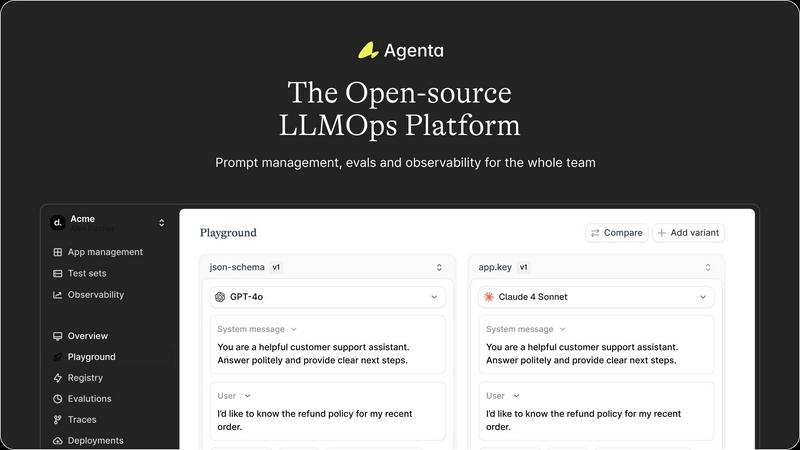
Agenta
OpenMark AI

Feature Comparison
Agenta
Unified Playground & Experimentation
Agenta provides a centralized playground where teams can iterate on prompts and compare different models side-by-side in real-time. This model-agnostic environment eliminates vendor lock-in, allowing you to use the best model from any provider. With complete version history for every prompt change, teams can track iterations, revert if needed, and maintain a clear audit trail of their development process, turning chaotic experimentation into a structured workflow.
Automated & Comprehensive Evaluation
Move beyond vibe checks with Agenta's systematic evaluation framework. It enables you to create a rigorous process to run experiments, track results, and validate every change before deployment. The platform supports any evaluator, including LLM-as-a-judge, custom code, and built-in metrics. Crucially, you can evaluate the full trace of an agent's reasoning, not just the final output, and seamlessly integrate human feedback from domain experts into the evaluation workflow.
Production Observability & Debugging
Gain deep visibility into your live LLM applications with comprehensive tracing. Agenta captures every request, allowing you to pinpoint exact failure points when things go wrong. You can annotate traces with your team or gather feedback directly from end-users. A powerful feature lets you turn any problematic production trace into a test case with a single click, closing the feedback loop and enabling continuous improvement based on real-world data.
Cross-Functional Collaboration Hub
Agenta breaks down silos by bringing product managers, domain experts, and developers into one unified workflow. It provides a safe, UI-based environment for non-technical experts to edit and experiment with prompts without touching code. Everyone can run evaluations, compare experiments, and contribute to the development process directly from the UI, while full API and UI parity ensures seamless integration between programmatic and manual workflows.
OpenMark AI
Plain Language Task Description
Simply describe the task you want to benchmark in natural language, without writing complex code or intricate prompt engineering. The platform's intuitive editor allows you to define your exact use case, from creative writing and translation to complex RAG and agentic workflows, making advanced benchmarking accessible to the entire product team.
Multi-Model Comparison in One Session
Run your identical prompt against dozens of leading models from providers like OpenAI, Anthropic, and Google simultaneously. This side-by-side testing eliminates the tedious process of manual, sequential API calls, delivering a unified results dashboard where you can directly compare performance, cost, and quality metrics head-to-head in minutes.
Real Cost & Stability Analysis
See the true cost per API request for your specific task and, more importantly, analyze output stability across multiple runs. OpenMark AI measures variance to show you which models deliver consistent, high-quality results every time, moving beyond a single data point to ensure reliability before you commit to a model for production.
Hosted Benchmarking with Credits
Skip the hassle of sourcing and configuring individual API keys for every model you want to test. The platform operates on a credit system, providing direct access to its extensive model catalog. This streamlined approach dramatically reduces setup time and operational overhead, letting you focus purely on evaluation and decision-making.
Use Cases
Agenta
Scaling Prototypes to Production
Teams with a working LLM prototype often struggle with the "last mile" to a reliable, scalable product. Agenta provides the structured workflow needed to systematically test, evaluate, and monitor changes. It replaces ad-hoc deployments with evidence-based releases, ensuring that performance improvements are real and regressions are caught early, dramatically increasing the success rate of launching AI features.
Centralizing Dispersed Prompt Management
When prompts are scattered across Slack, Google Sheets, and emails, consistency and version control are impossible. Agenta serves as the single source of truth for all prompt versions and configurations. This centralization prevents drift, allows for easy rollback, and ensures every team member is always working with the latest, approved iteration, eliminating costly errors and miscommunication.
Implementing Rigorous Evaluation Frameworks
For teams relying on manual "vibe testing," Agenta introduces a data-driven evaluation culture. You can build automated test suites that run against every proposed change, using LLM judges, code-based checks, and human-in-the-loop feedback. This creates a systematic gatekeeping process for production, building confidence that new prompts or model configurations actually improve key metrics before they impact users.
Debugging Complex Agentic Workflows
Debugging a failing LLM agent with multiple reasoning steps is notoriously difficult. Agenta's full-trace observability allows developers to see every intermediate step, input, and output. When an error occurs, engineers can drill down to the exact API call or reasoning step that failed, dramatically reducing mean-time-to-resolution (MTTR) and turning debugging from guesswork into a precise science.
OpenMark AI
Pre-Deployment Model Validation
Before shipping a new AI feature, product teams can rigorously test candidate models on their actual task. This validates which model delivers the required quality at an acceptable cost and latency, de-risking development and preventing costly post-launch model switches.
Cost-Efficiency Optimization for Scaling Applications
For applications generating high volumes of AI calls, finding the most cost-effective model is critical. Developers use OpenMark to benchmark models not just on headline token price, but on the real cost-to-quality ratio for their workload, optimizing operational expenses as user demand grows.
Ensuring Output Consistency and Reliability
When building features where predictable performance is non-negotiable—like data extraction or classification—teams benchmark models across multiple runs. This identifies which providers offer stable, low-variance outputs, ensuring end-users have a reliable and consistent experience.
Rapid Prototyping and Model Selection
During the ideation phase, developers can quickly test which LLMs are best suited for a new concept. By describing the prototype task, they can get immediate feedback on quality and capability across the model landscape, accelerating the initial design and technical feasibility assessment.
Overview
About Agenta
Agenta is the open-source LLMOps platform engineered to transform how AI teams build and scale. It directly tackles the core chaos of modern AI development, where prompts are scattered across communication tools, teams operate in silos, and deployment is a leap of faith. Agenta provides the essential infrastructure to implement a structured, collaborative, and evidence-based workflow, serving as the single source of truth for developers, product managers, and subject matter experts. It is built for teams serious about moving fast without breaking things, enabling them to iterate smarter, validate thoroughly, and scale their LLM applications efficiently from fragile prototypes to robust, production-grade systems. By centralizing prompt management, automated evaluation, and comprehensive observability, Agenta empowers teams to replace guesswork with data-driven decisions, debug with precision, and ship reliable AI features with confidence.
About OpenMark AI
OpenMark AI is the definitive platform for task-level LLM benchmarking, built to eliminate the guesswork from choosing AI models. It's a web application where developers and product teams describe their specific task in plain language—like data extraction, classification, or agent routing—and run comprehensive benchmarks against a vast catalog of over 100 models in a single session. The platform delivers side-by-side comparisons of real API performance, moving beyond theoretical datasheets to show you actual cost per request, latency, scored output quality, and critical stability metrics across repeat runs. This focus on variance reveals consistency, not just a single lucky output, ensuring your AI feature is built on a reliable foundation. By using a hosted credit system, OpenMark AI removes the friction of configuring and managing multiple API keys, accelerating your pre-deployment validation. It's designed for teams who prioritize cost efficiency and performance at scale, helping you ship with confidence by pinpointing the optimal model for your unique workflow and budget.
Frequently Asked Questions
Agenta FAQ
Is Agenta really open-source?
Yes, Agenta is a fully open-source platform. You can dive into the code on GitHub, contribute to the project, and self-host the entire platform. This ensures transparency, avoids vendor lock-in, and allows for deep customization to fit your specific infrastructure and workflow needs.
How does Agenta handle collaboration for non-technical team members?
Agenta features a dedicated, user-friendly web interface that allows product managers and domain experts to participate directly in the LLM development lifecycle. They can safely edit prompts in a visual playground, set up and view evaluation results, and provide feedback on traces without writing a single line of code, fostering true cross-functional collaboration.
Can I use Agenta with my existing tech stack?
Absolutely. Agenta is designed to be framework and model-agnostic. It seamlessly integrates with popular frameworks like LangChain and LlamaIndex, and can work with models from any provider, including OpenAI, Anthropic, Azure, and open-source models. It complements your existing tools rather than forcing a replacement.
What is the difference between evaluation and observability in Agenta?
Evaluation in Agenta refers to the systematic, often automated, testing of LLM variants against predefined metrics and test sets before deployment. Observability is about monitoring live, production systems, capturing traces, and gathering real-user feedback to detect issues and regressions. Agenta connects both: a production issue (observability) can instantly become a test case (evaluation), closing the loop.
OpenMark AI FAQ
How does OpenMark AI differ from standard model leaderboards?
Standard leaderboards use fixed, generalized datasets (like MMLU) that may not reflect your specific use case. OpenMark AI performs benchmarking with your prompts and tasks, providing real API cost, latency, and stability data from models running your exact workload, giving you actionable insights for your product.
Do I need my own API keys to use OpenMark AI?
No. OpenMark AI uses a hosted credit system. You purchase credits and the platform manages API access to its extensive catalog of models. This eliminates the need to sign up for and configure multiple provider accounts and keys, streamlining the entire benchmarking process.
What does "stability" or "variance" testing mean?
When you run a benchmark, OpenMark AI can execute your task multiple times with the same model. Stability analysis shows how much the outputs and scores vary across these runs. A model with low variance is more predictable and reliable for production, whereas high variance indicates inconsistent performance.
What kind of tasks can I benchmark on OpenMark AI?
You can benchmark virtually any LLM task. Common examples include text classification, summarization, translation, creative writing, code generation, data extraction, question answering, complex reasoning, and evaluating components of RAG pipelines or multi-agent systems. Describe your task in plain language to get started.
Alternatives
Agenta Alternatives
Agenta is an open-source LLMOps platform designed to help teams build and scale reliable AI applications. It belongs to the rapidly evolving category of tools focused on managing the lifecycle of large language models, from experimentation to production. Teams often explore alternatives for various strategic reasons. These can include specific budget constraints, the need for different feature sets like deeper MLOps integration, or a requirement for a fully managed service versus an open-source framework. The right fit depends heavily on a team's existing tech stack, in-house expertise, and growth trajectory. When evaluating options, consider your core needs: a collaborative workflow for cross-functional teams, robust evaluation and testing capabilities to ensure quality, and comprehensive observability to debug and improve systems. The goal is to find a platform that provides structure without sacrificing the agility needed to innovate quickly in the AI space.
OpenMark AI Alternatives
OpenMark AI is a developer tool for task-level LLM benchmarking, helping teams choose the right model before shipping an AI feature. Users often explore alternatives to find a solution that better fits their specific budget, required feature set, or integration needs with their existing platform. When evaluating other options, it's crucial to look beyond basic model lists. Consider whether the tool provides real, side-by-side performance data from actual API calls, measures stability across multiple runs, and calculates true cost efficiency for your specific task, not just token price. The goal is to find a benchmarking solution that delivers actionable insights for pre-deployment validation. This means seeing variance in outputs, understanding latency trade-offs, and getting a clear picture of which model offers the best quality relative to its cost for your unique workflow.