Friendli Engine
About Friendli Engine
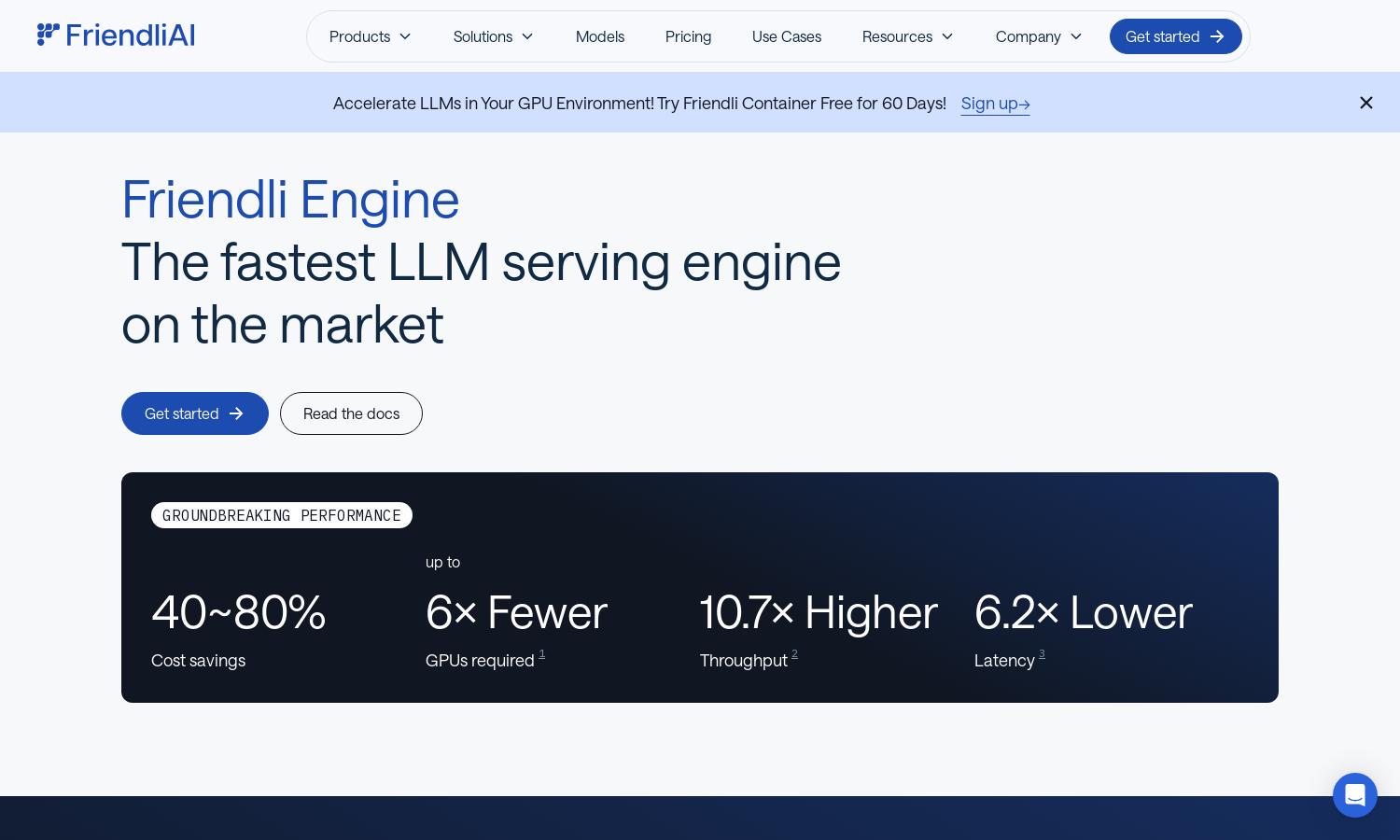
Friendli Engine specializes in fast and cost-effective LLM inference, catering to developers and businesses in generative AI. Its innovative features such as iteration batching and TCache enable users to achieve exceptional performance with significant cost savings, transforming how LLMs are deployed and utilized.
Friendli Engine offers flexible pricing plans, designed to accommodate various user needs. From free trials to subscription tiers with added benefits, users can choose a plan that best suits their requirements, enhancing their generative AI capabilities while enjoying significant savings on processing costs.
The user interface of Friendli Engine is intuitively designed for seamless navigation, enhancing user experience. Its streamlined layout features easy access to features like real-time performance analytics and model customization, ensuring that users can efficiently manage and deploy their AI models with minimal hassle.
How Friendli Engine works
Users begin by signing up for Friendli Engine, where they can easily onboard their generative AI models. Once logged in, they can explore features like Dedicated Endpoints or Containers to serve LLM inferences. The platform's unique iteration batching enables users to process multiple requests efficiently, saving both time and resources, while intelligent caching reduces GPU workload, enhancing overall performance.
Key Features for Friendli Engine
Iteration Batching Technology
Friendli Engine introduces innovative iteration batching technology that significantly increases LLM inference throughput. This unique feature allows users to handle multiple generation requests concurrently, resulting in an efficient and cost-effective experience, proving essential for high-demand environments in generative AI development.
Multi-LoRA Model Support
The Friendli Engine's ability to support multiple LoRA models on a single GPU represents a significant advancement in generative AI. This feature simplifies model customization and enhances efficiency, allowing users to deploy various applications without the need for extensive GPU resources, ultimately lowering costs.
Speculative Decoding
Speculative decoding is a key feature of Friendli Engine that accelerates inference times. By predicting future tokens while generating the current token, it retains model output accuracy while significantly reducing latency, making it an indispensable tool for applications requiring rapid response times in generative AI.
You may also like: